type
status
date
slug
summary
tags
category
icon
password
Motivation
Online SoftMax
- Self-attention(ignore attention masks and scale factor for simplicity)
- X =
- A =
- O=AV
- SoftMax: will exceed the effective range of FP16 if x 11
- Safe-SoftMax:
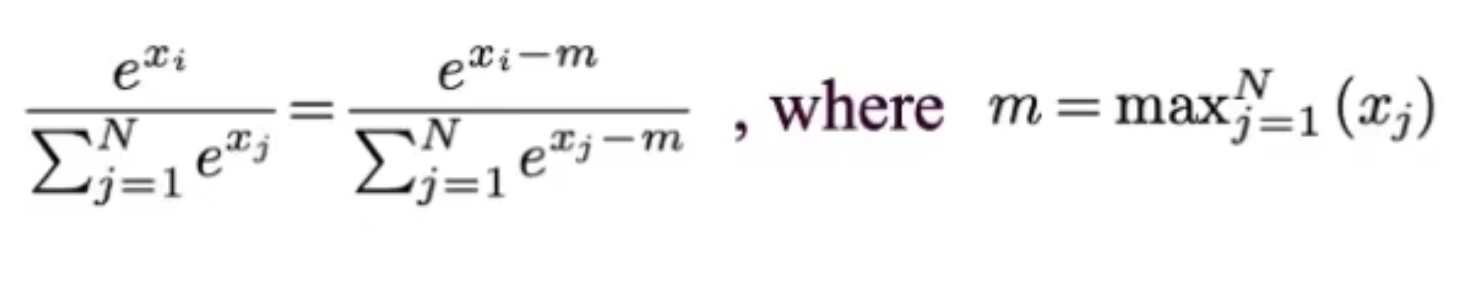
- Algorithm: 3-pass safe SoftMax NOT I/O efficient

- Idea: combine those for loops together, diminish I/O
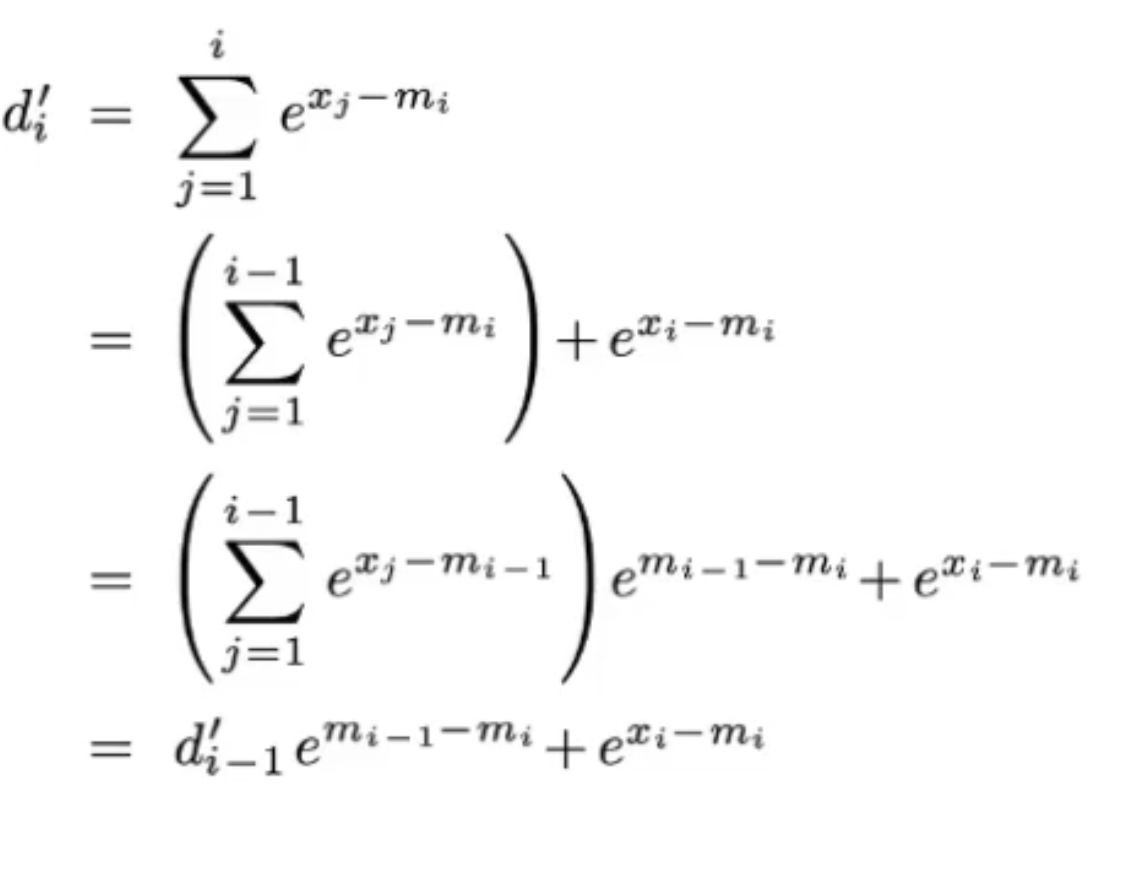
- Changes: Use m_i to represent d'_i-1, instead of m_N
- After change:

- Note: impossible to have 1-pass online SoftMax here
Tiling

- How to divide into tiles: depends on SRAM on chips
Flash Attention-2
Motivation
- Flash Attention is worse than hand-tuned GEMMs
- The forward pass only reaches 30-50%of the theoretical maximum FLOPs/s of the device
- The backward pass only reaches 25-35%of the theoretical maximum FLOPs/s of the device
- Optimized GEMM can reach up to 80-90%of the theoretical maximum device throughput
- Observation
- Non-MatMul FLOPs can be further reduced
- The sequence length dimension can be further parallelized
- I/O between warps and shared memory can be further reduced