type
status
date
slug
summary
tags
category
icon
password
Transformer
Vector
One-hot Encoding
- No relationship
Word Embedding
What is the output
- Each vector has a label
- POS tagging: e.g. v. / adj. / n.
- The whole sequence has a label
- Give a sentence, output positive/negative
- Model decides the number of labels itself
- Translation
Sequence Labeling
Fully connected network
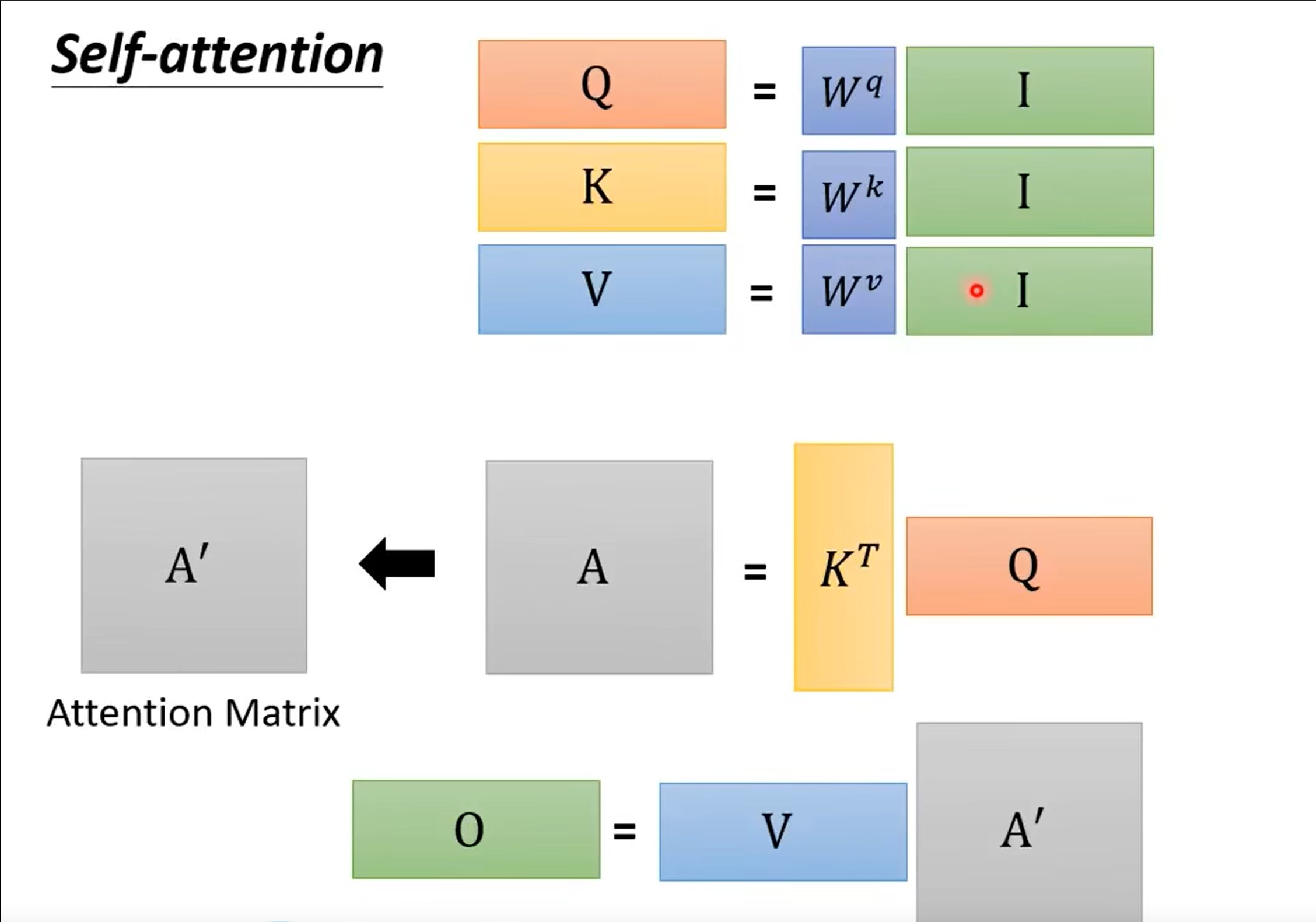
Self-attention

- Input a token, then output a token that considered the whole sequence
- Input can be either input or a hidden layer
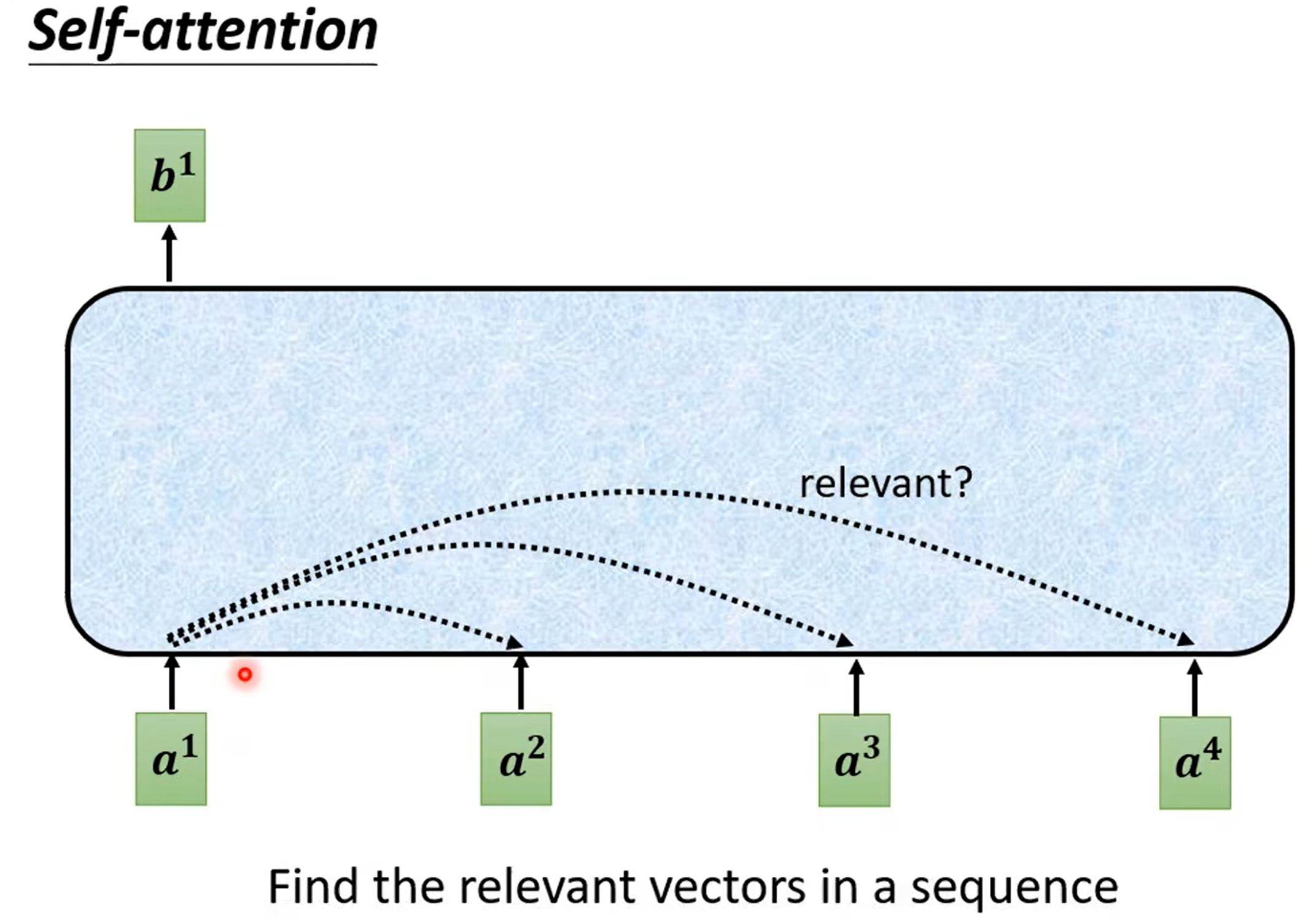
- Find the relevant vectors in a sequence
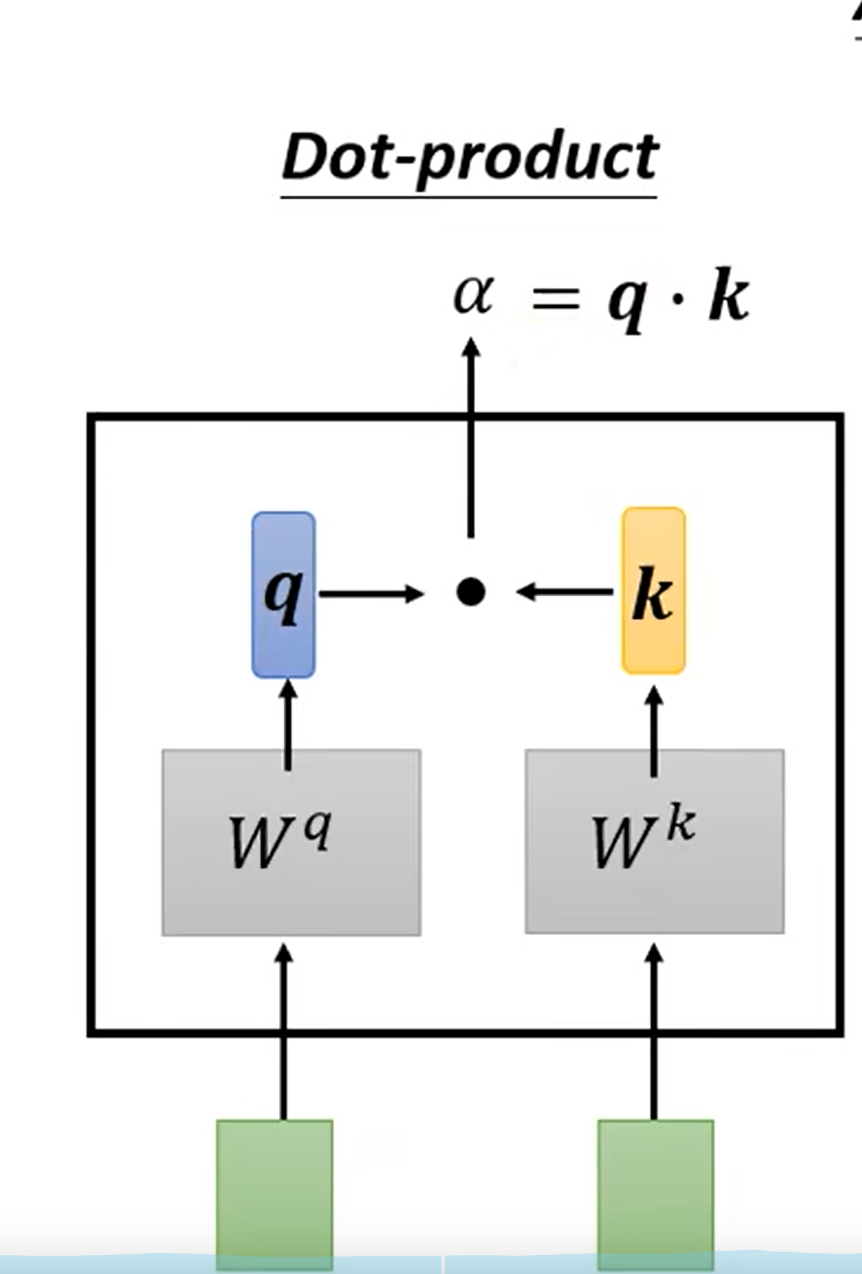
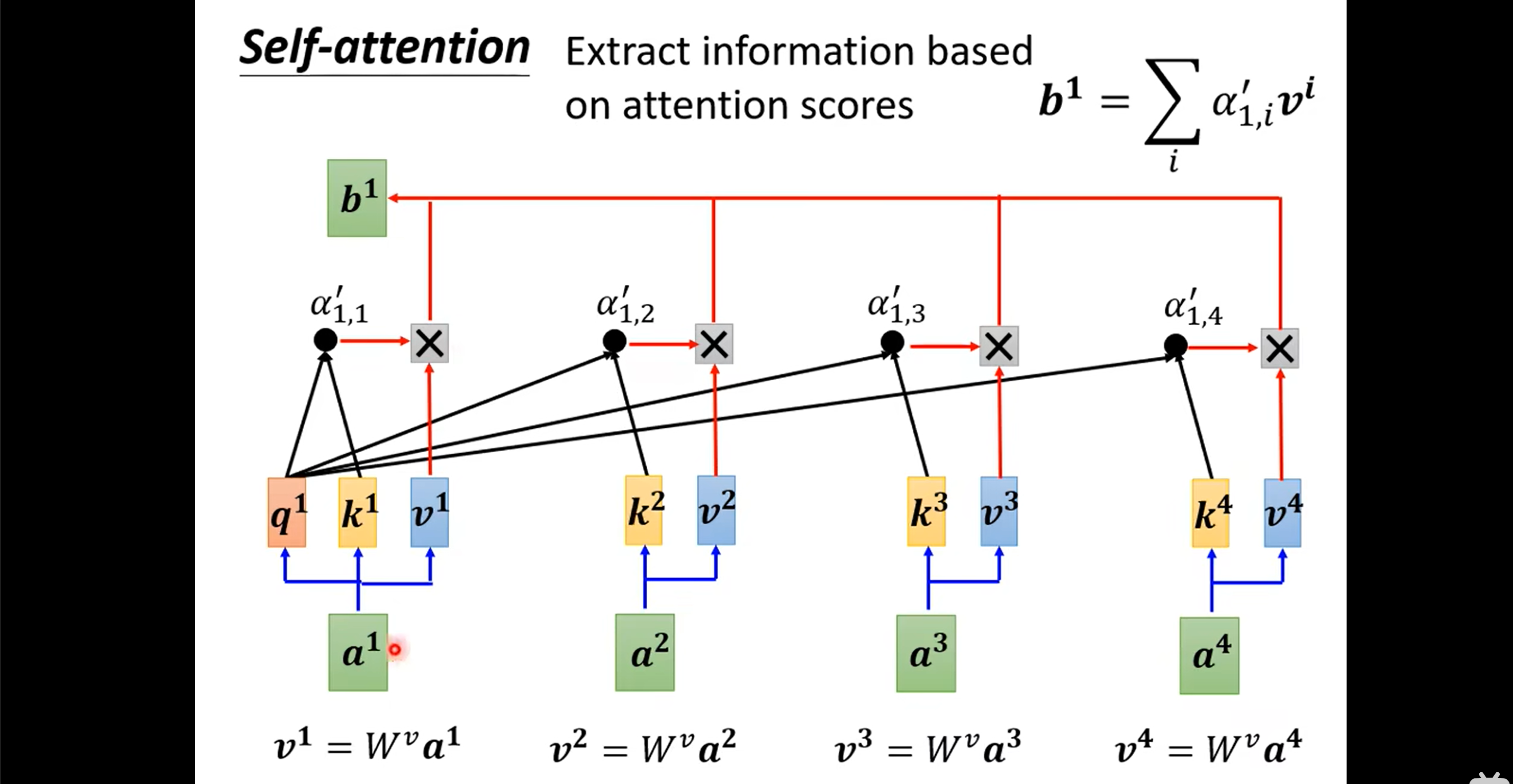
- Only three parameters to be trained: $W_q, W_k, W_v$
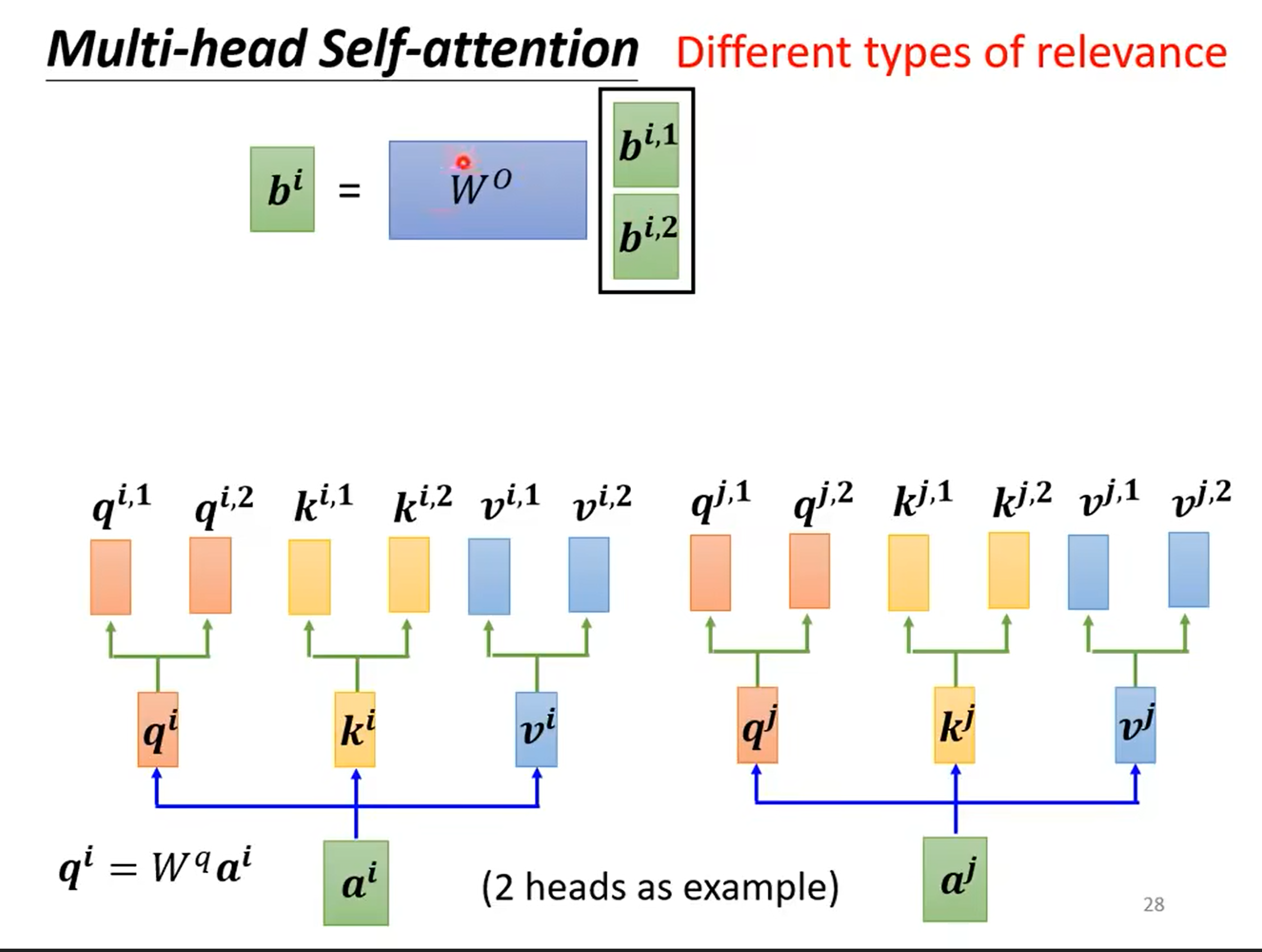
- Multi-head self-attention
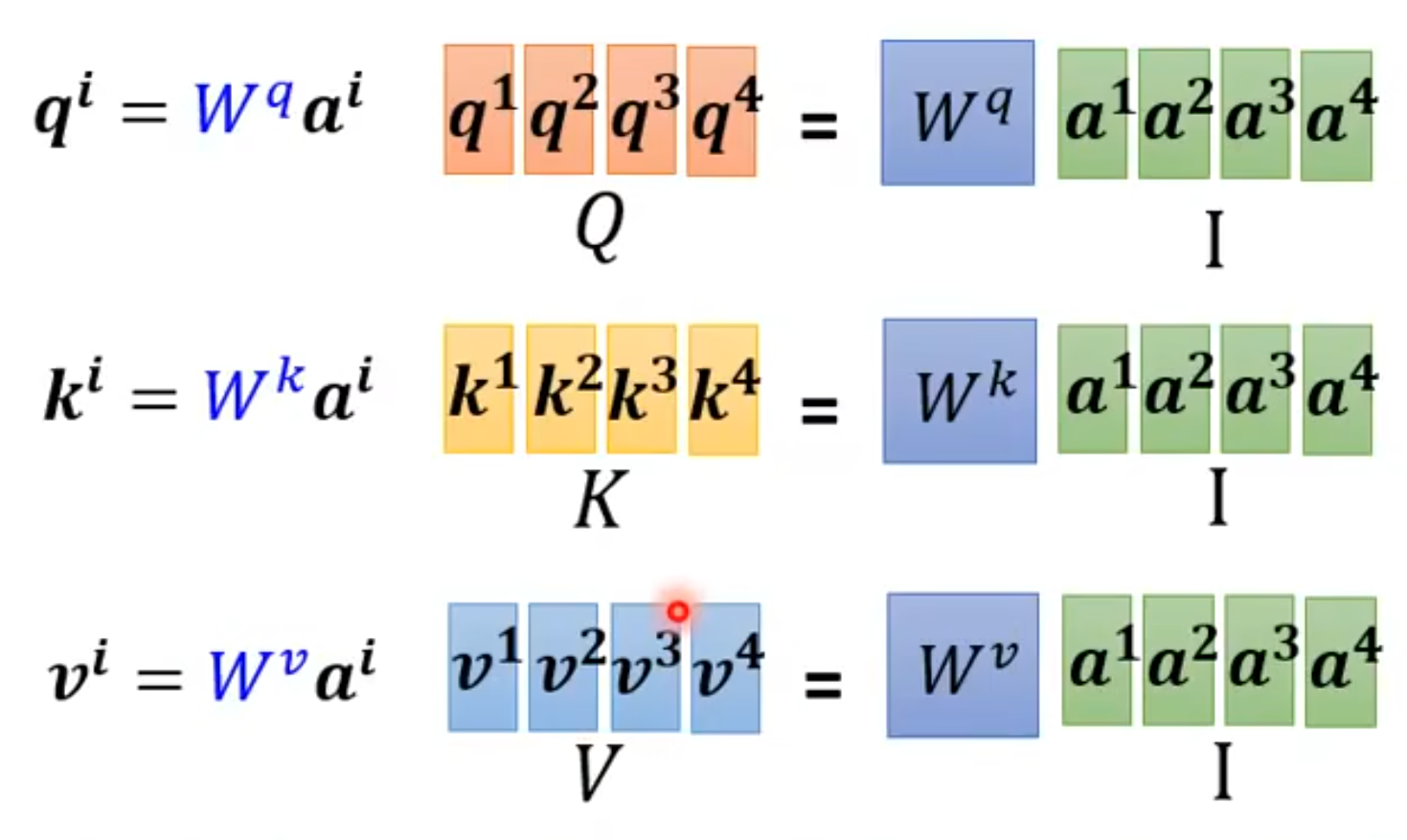
Positional Encoding
- No position information in self-attention
- Each position has a unique positional vector $e^i$
- Hand-crafted
- Method
- Sinusoidal
- Embedding
- Relative
- FLOATER
- RNN
Self-attenton applications
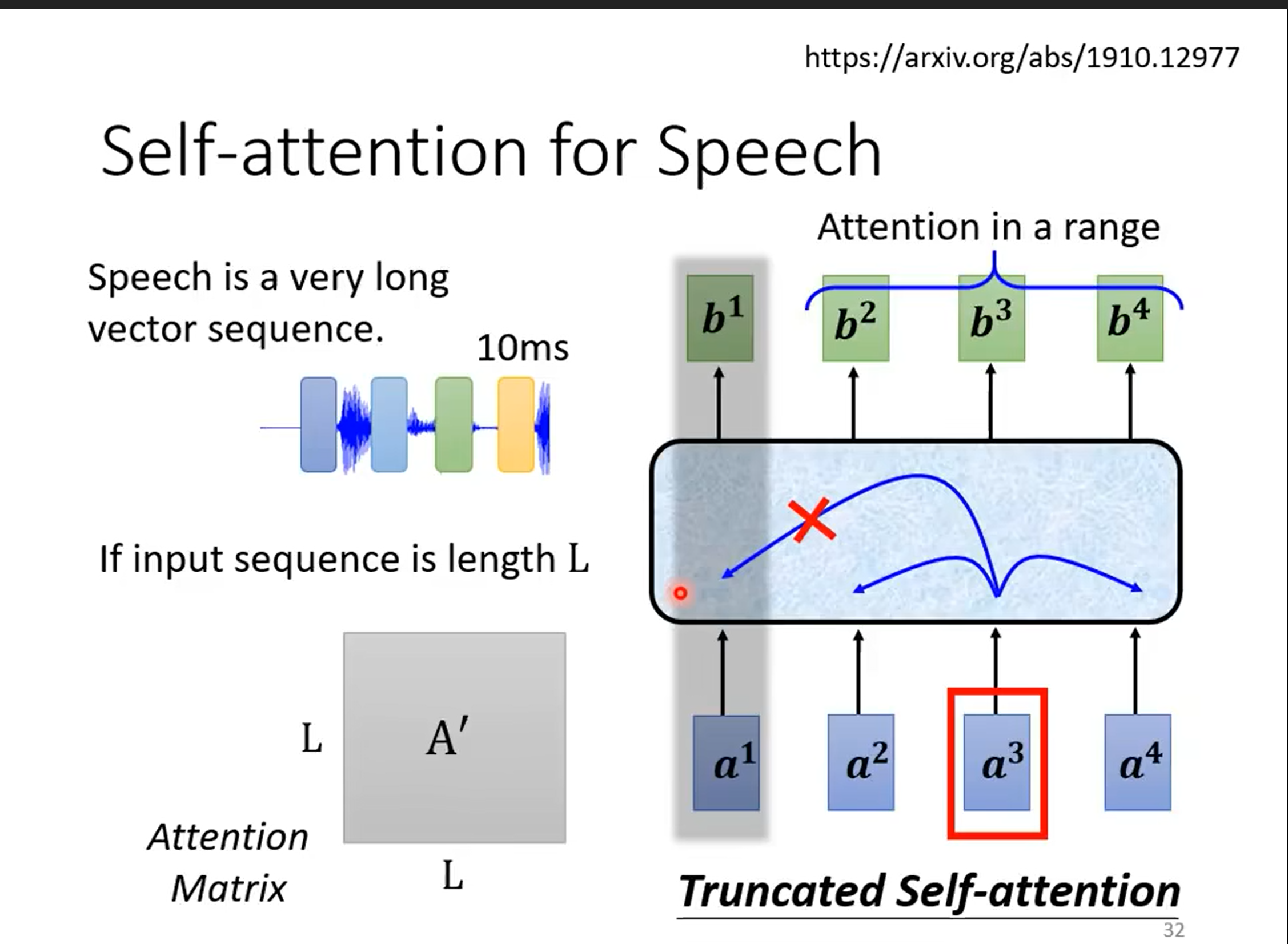
Speech
Image
- CNN: self-attention that can only attends in a receptive field
- CNN is simplified self-attention.
- Self-attention: CNN with learnable receptive field
- Self-attention is the complex version of CNN
- Self-attention vs. CNN

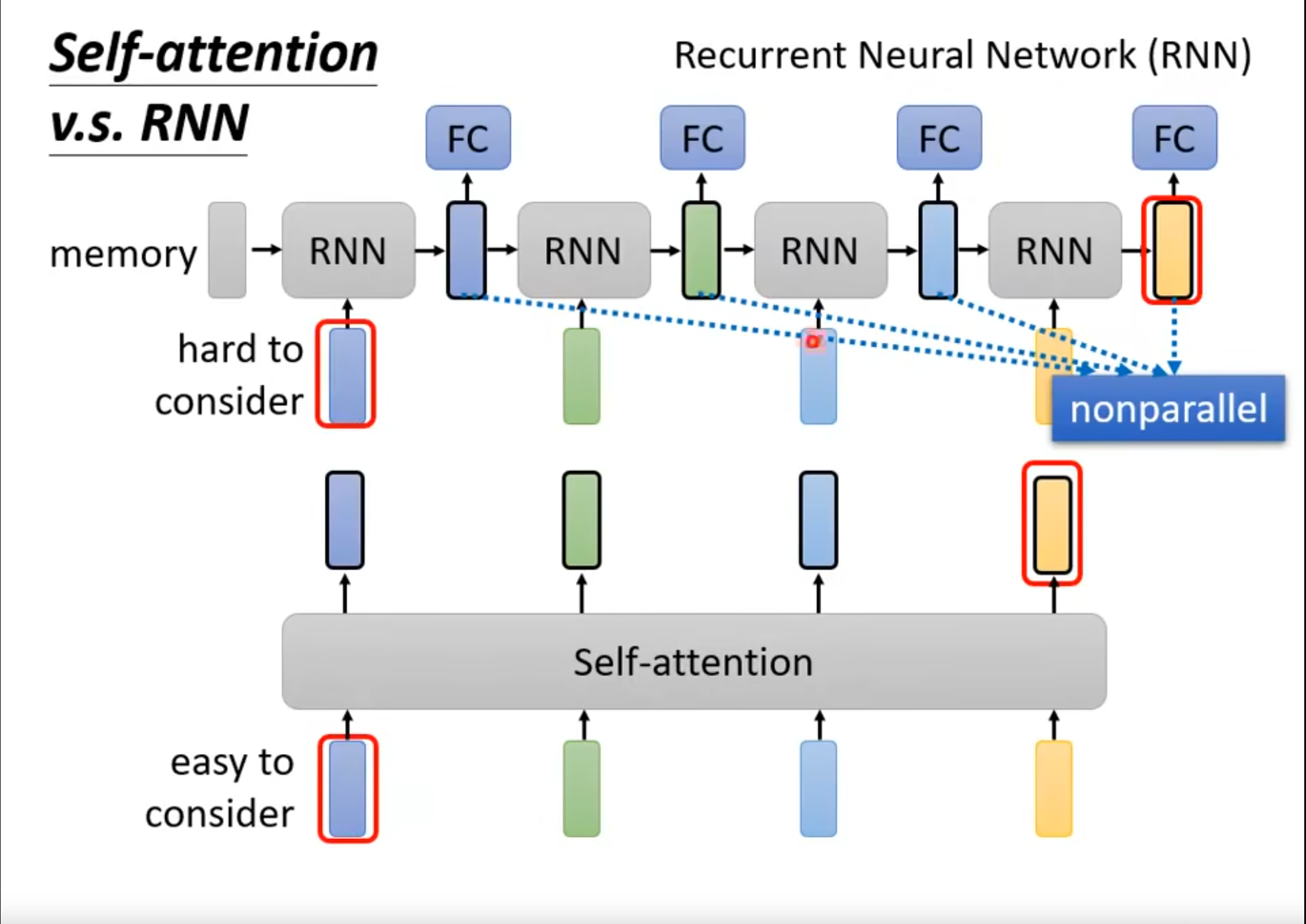
- Self-attention vs. RNN(Recurrent Neural Network)
Graph
- Consider edge: only attention to connected nodes
Other applications
Sequence-to-sequence (Seq2seq)
Input a sequence, output a sequence
- The output length is determined by model
Seq2seq for chatbot
- Input seq2seq response
- Question Answering
- Can be done by seq2seq
- question, context seq2seq answer
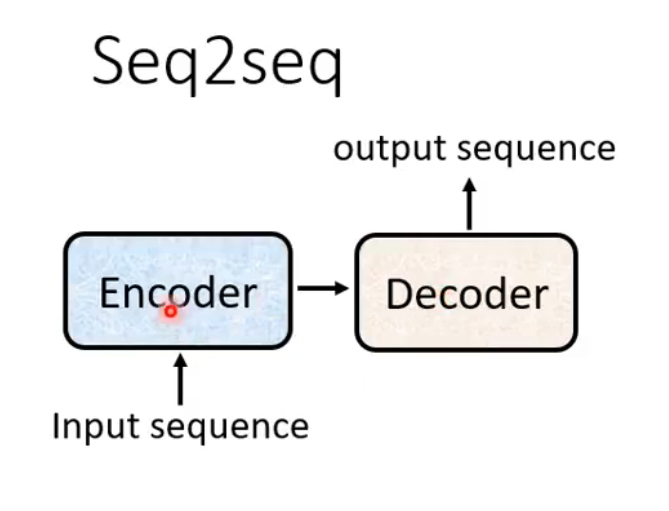
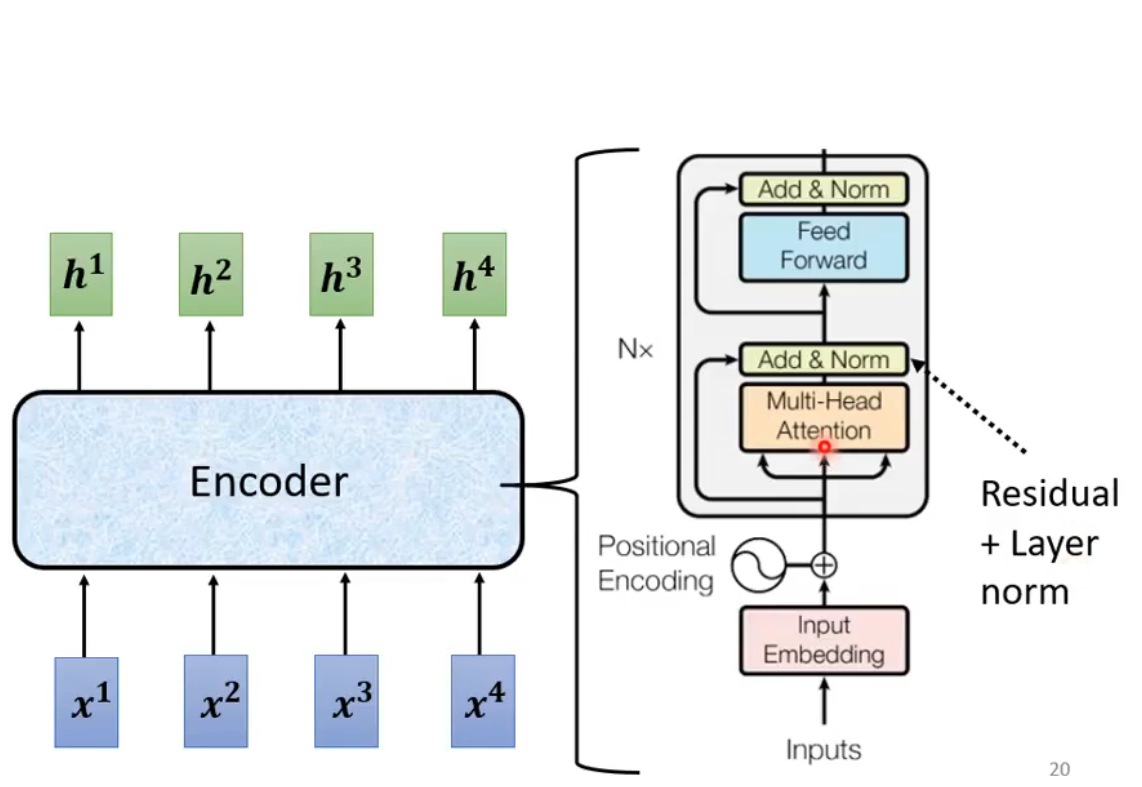
Encoder
- Input a vector sequence, output a vector sequence
Fully connected Network
- The neurons in each layer are all connected to the neurons in the next layer
- Each layer receives global information and lacks the ability for local perception
Layer Normalization vs. Batch Normalization
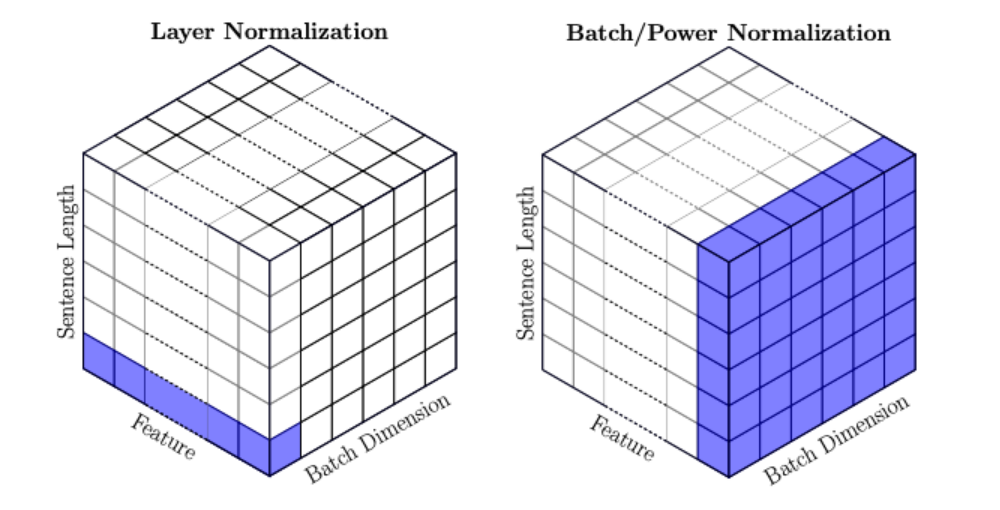
- Layer: One instance, all features in all dimension
- Batch: All instances, one features in one dimension
Diff
- If we organize a batch of texts into a batch, the operation direction of Batch Normalization (BN) is to act on the first word of each sentence. However, the complexity of linguistic text is very high. Any word might be placed at the beginning, and the order of words may not affect our understanding of the sentence. BN scales each position, which does not conform to the rules of NLP.
- On the other hand, Layer Normalization (LN) scales according to each sentence, and LN is generally used in the third dimension, such as 'dims' in [batchsize, seq_len, dims], which is usually the dimension of word vectors, or the output dimension of RNN, etc. This dimension should have the same scale for all features. Therefore, it will not encounter the scaling problem caused by different scales of features as mentioned above